Preprocessing the data is important for many reasons.
For function mapping problems the most powerful method, to our knowledge,
for extracting functional dependencies between input and output
is the so-called  -test [61]. This test only assumes
that the function is continuous and uses conditional
probabilities to select the significant input variables.
-test [61]. This test only assumes
that the function is continuous and uses conditional
probabilities to select the significant input variables.
Normalization of the input is done to prevent ``stiffness'', i.e. when
weights need to be updated with very different learning rates. Two
simple normalization options are; either scale the inputs to
the range 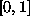 , or translate them to their mean values and rescale to
unit variance. The former method is useful if the data is more or less
evenly
distributed over a limited range, whereas the latter is useful when the
data contains outliers. In some cases, such normalizations reduce the
learning time for the network by an order of magnitude.
, or translate them to their mean values and rescale to
unit variance. The former method is useful if the data is more or less
evenly
distributed over a limited range, whereas the latter is useful when the
data contains outliers. In some cases, such normalizations reduce the
learning time for the network by an order of magnitude.
A method suggested in [26] is to let the network handle the normalization by adding an extra layer of units. This is useful if the data is not available beforehand to compute the relevant scales.