The user interface common blocks are /JNDAT1/ and /JNDAT2/. /JNDAT1/ is the main common block while /JNDAT2/ is intended for the "advanced" user.
MSTJN is a vector of switches used to define the feed-forward network used:MSTJN(1) (D=3) number of layers in the net
MSTJN(2) (D=10) number of patterns per update in JNTRAL
MSTJN(3) (D=1) overall activation function used in the net
1
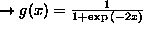
2
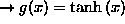
3
(only used internally for Potts-nodes)
4
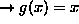
5
(only used internally for entropy error)
MSTJN(4) (D=0) error measure
-1
log-squared error:
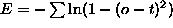
0
summed square error:
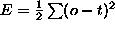
1
entropy error:
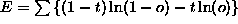
2
Kullback error with Potts nodes of dimension MSTJN(4)
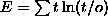
MSTJN(5) (D=0) updating procedure
0
normal updating
1
Manhattan updating
2
Langevin updating
3
Quickprop updating
4
Conj. Grad. updating -- Polak-Ribiere
5
Conj. Grad. updating -- Hestenes-Stiefel
6
Conj. Grad. updating -- Fletcher-Reeves
7
Conj. Grad. updating -- Shanno
8
terminate Conj. Grad. updating
9
no updating
10
Scaled Conj. Grad. updating -- Polak-Ribiere
11
Scaled Conj. Grad. updating -- Hestenes-Stiefel
12
Scaled Conj. Grad. updating -- Fletcher-Reeves
13
Scaled Conj. Grad. updating -- Shanno
14
terminate Scaled Conj. Grad. updating
15
Rprop updating
MSTJN(6) (D=6) file number for output statistics
MSTJN(7) (R) number of calls to JNTRAL
MSTJN(8) (I) initialization done
MSTJN(9) (D=100) number of updates per epoch
MSTJN(10+I) number of nodes in layer I (I=0
input layer)
MSTJN(10) (D=16)
MSTJN(11) (D=8)
MSTJN(12) (D=1)
MSTJN(13-20) (D=0)
MSTJN(21) (D=0) pruning (
on)
MSTJN(22) (D=0) saturation measure s (
on)
MSTJN(23,24) (D=0) (x,y)-geometry of input field when using receptive fields
periodic boundary conditions
see COMMON /JNINT3/ for further explanations
MSTJN(25,26) (D=0) (x,y)-geometry of receptive fields
MSTJN(27) (D=1) number of hidden nodes per receptive field
MSTJN(28-30) (D=0) bit-precision (
machine precision) for sigmoid
functions (28), thresholds (29) and weights (30)
MSTJN(31) (D=1) procedure for handling warnings
warnings are ignored
execution is terminated after MSTJN(32) warnings
in any case, only MSTJN(32) warning messages are issued
MSTJN(32) (D=10) maximum number of warning messages to be issued
(see description above)
MSTJN(33) (I) code for latest warning issued by the program
MSTJN(34) (I) number of warnings issued by the program so far
MSTJN(35) (D=10) maximum number of iterations allowed in line search
MSTJN(36) (D=10) maximum number of allowed restarts for the line search
MSTJN(37) (I) current status of the line search
minimum found
searching for minimum
MSTJN(38) (I) number of restarts in QP/CG/SCG
MSTJN(39) (I) number of calls to JNHESS
MSTJN(40) not used.
Switches 2, 5, 6, 21, 22, 28, 29, 30, 31, 32, 35 and 36 can be changed at any time by the user.
PARJN is a vector of parameters determining the performance of the feed-forward net:
PARJN(1) (D=0.001) learning rate
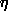
PARJN(2) (D=0.5) momentum parameter
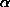
PARJN(3) (D=1.0) overall inverse network temperature
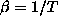
PARJN(4) (D=0.1) width
of initial weights
[- PARJN(4), PARJN(4)]
[0,- PARJN(4)]
PARJN(5) (D=0.0) weight decay parameter
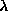
PARJN(6) (D=0.0) width
of Gaussian noise in Langevin updating
PARJN(7) (R) last error per node
PARJN(8) (R) mean error in last update
PARJN(9) (R) mean error last epoch (equal to MSTJN(9) updates)
PARJN(10) (R) weighted average error
used when pruning
PARJN(11) (D=1.0) decrease in
(scale factor per epoch)
``bold driver'' dynamics
geometric decrease
PARJN(12) decrease in momentum alpha (scale factor per epoch).
PARJN(13) (D=1.0) decrease in temperature T (scale factor per epoch)
PARJN(14) (D=0.0) pruning parameter
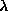
PARJN(15) (D=
) change
of
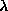
PARJN(16) (D=0.9) parameter
used for calculation of PARJN(10)
PARJN(17) (D=0.9) pruning rescaling factor c
PARJN(18) (D=1.0) scale parameter
used in pruning
PARJN(19) (D=0.0) target error D used in pruning
PARJN(20) (D=1.0) decrease in Langevin noise (scale factor per epoch)
PARJN(21) (D=1.75) maximum scale in QP updating
PARJN(22) (D=1000.0) maximum allowed size of weights in QP
PARJN(23) (D=0.0) constant added to
to avoid ``flat spot'' in QP
PARJN(24) (D=0.1) line search convergence parameter

PARJN(25) (D=0.05) tolerance
of minimum in line search
PARJN(26) (D=0.001) minimum allowed change in error in line search
PARJN(27) (D=2.0) maximum allowed step size in line search
PARJN(28) (D=
) constant
used in SCG for computing s
PARJN(29) (D=
) initial value for
in SCG
PARJN(30) (D=1.2) scale-up factor
used in Rprop
PARJN(31) (D=0.5) scale-down factor
used in Rprop
PARJN(32) (D=50.0) maximum scale-up factor in Rprop
PARJN(33) (D=
) minimum scale-down factor in Rprop
PARJN(34-40) not used
All parameters can be changed at any time by the user.
(See [1] for descriptions on switches MSTJM and parameters PARJM.)
OIN is the vector used to pass the values of the input nodes to the
program.
OUT is a vector used both to pass the desired value of the output nodes to
the program during supervised training and to pass the output produced by the
network given an input pattern in OIN.
TINV(I) (D=0.0) if greater than 0.0, this value is used as inverse temperature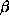
in the sigmoid function for layer I, otherwise the overall inverse
temperature PARJN(3) is used. Can be changed at any time by
the user.
IGFN(I) (D=0) if greater than 0, these switches determine the sigmoid function
to be used in layer I, otherwise the overall function determined
by MSTJN(3) is used. These switches are only active before the
network is initialized with subroutine JNINIT.
ETAL(I) (D=0.0) if greater than 0.0, this value is used for the learning rate
for
weights in weight layer I. The weights between input and first
hidden layer is considered to be weight layer number one. Can
be changed at any time by the user.
WIDL(I) (D=0.0) if greater than 0.0, this value is used for the width
for initial
weight values in weight layer I.
SATM(I) (R) if MSTJN(22)
0 this vector contains the average saturation
of nodes in layer I.