The BP algorithm, eq. (![]() ), is selected by setting MSTJN(5)
= 0 (default). Its main parameters are
the learning rate PARJN(1) (
), is selected by setting MSTJN(5)
= 0 (default). Its main parameters are
the learning rate PARJN(1) (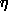 in eq. (
in eq. (![]() )), the momentum
PARJN(2) (
)), the momentum
PARJN(2) (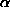 in eq. (
in eq. (![]() )), and the number
of patterns per update MSTJN(2). We strongly advocate the use of an
on-line updating procedure where MSTJN(2) is small. Routinely we use
ten patterns per update for most applications -- occasionally an order of
magnitude more. The learning rate is the parameter that requires most
attention. Typical initial values are in the range
)), and the number
of patterns per update MSTJN(2). We strongly advocate the use of an
on-line updating procedure where MSTJN(2) is small. Routinely we use
ten patterns per update for most applications -- occasionally an order of
magnitude more. The learning rate is the parameter that requires most
attention. Typical initial values are in the range 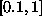 and
it is usually profitable to scale the learning rate in inverse proportion
to the fan-in of the units so that different learning rates are used for
different weight layers. The momentum should be in the range [0,1]. For HEP
problems momentum values above 0.5 are seldom required. For
parity problems and such, a momentum value close to unity is needed.
and
it is usually profitable to scale the learning rate in inverse proportion
to the fan-in of the units so that different learning rates are used for
different weight layers. The momentum should be in the range [0,1]. For HEP
problems momentum values above 0.5 are seldom required. For
parity problems and such, a momentum value close to unity is needed.
In contrast to earlier versions, JETNET 3.0 uses a normalized error to make the gradient, and hence the learning parameters are independent of the number of patterns used per update.