Rprop ( MSTJN(5) = 15) uses individual learning rates that are dynamically
tuned during training according to eq. (![]() ). It has two learning
parameters and two control parameters besides the learning rates
(in vector ETAV); the scale factors
). It has two learning
parameters and two control parameters besides the learning rates
(in vector ETAV); the scale factors 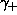 and
and
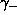 ( PARJN(28-29)) and the maximum allowed scale-up and
scale-down factors ( PARJN(30-31)). According to
[59] the final result is not very sensitive to the choice of the scale
factors. Hence the only concern are the initial learning rates, which are set
as in the BP case. JETNET uses the value stored in PARJN(1) or
ETAL to initialize the learning rates.
( PARJN(28-29)) and the maximum allowed scale-up and
scale-down factors ( PARJN(30-31)). According to
[59] the final result is not very sensitive to the choice of the scale
factors. Hence the only concern are the initial learning rates, which are set
as in the BP case. JETNET uses the value stored in PARJN(1) or
ETAL to initialize the learning rates.