Support Vector Machine. More...
#include <yat/classifier/SVM.h>
Public Member Functions | |
| SVM (void) | |
| Constructor. | |
| SVM (const SVM &) | |
| Copy constructor. | |
| virtual | ~SVM () |
| Destructor. | |
| SVM * | make_classifier (void) const |
| Create an untrained copy of SVM. | |
| const utility::Vector & | alpha (void) const |
| double | C (void) const |
| unsigned long int | max_epochs (void) const |
| void | max_epochs (unsigned long int) |
| set maximal number of epochs in training | |
| const theplu::yat::utility::Vector & | output (void) const |
| void | predict (const KernelLookup &input, utility::Matrix &predict) const |
| void | reset (void) |
| make SVM untrained | |
| void | set_C (const double) |
| sets the C-Parameter | |
| void | train (const KernelLookup &kernel, const Target &target) |
| bool | trained (void) const |
Detailed Description
Support Vector Machine.
Member Function Documentation
| const utility::Vector& theplu::yat::classifier::SVM::alpha | ( | void | ) | const |
- Returns:
- alpha parameters
| double theplu::yat::classifier::SVM::C | ( | void | ) | const |
The C-parameter is the balance term (see train()). A very large C means the training will be focused on getting samples correctly classified, with risk for overfitting and poor generalisation. A too small C will result in a training, in which misclassifications are not penalized. C is weighted with respect to the size such that 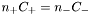 , meaning a misclassificaion of the smaller group is penalized harder. This balance is equivalent to the one occuring for regression with regularisation, or ANN-training with a weight-decay term. Default is C set to infinity.
, meaning a misclassificaion of the smaller group is penalized harder. This balance is equivalent to the one occuring for regression with regularisation, or ANN-training with a weight-decay term. Default is C set to infinity.
- Returns:
- mean of vector
| SVM* theplu::yat::classifier::SVM::make_classifier | ( | void | ) | const |
| unsigned long int theplu::yat::classifier::SVM::max_epochs | ( | void | ) | const |
Default is max_epochs set to 100,000.
- Returns:
- number of maximal epochs
| const theplu::yat::utility::Vector& theplu::yat::classifier::SVM::output | ( | void | ) | const |
The output is calculated as 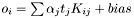 , where
, where 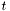 is the target.
is the target.
- Returns:
- output of training samples
| void theplu::yat::classifier::SVM::predict | ( | const KernelLookup & | input, |
| utility::Matrix & | predict | ||
| ) | const |
Generate prediction predict from input. The prediction is calculated as the output times the margin, i.e., geometric distance from decision hyperplane: 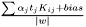 The output has 2 rows. The first row is for binary target true, and the second is for binary target false. The second row is superfluous as it is the first row negated. It exist just to be aligned with multi-class SupervisedClassifiers. Each column in input and output corresponds to a sample to predict. Each row in input corresponds to a training sample, and more exactly row i in input should correspond to row i in KernelLookup that was used for training.
The output has 2 rows. The first row is for binary target true, and the second is for binary target false. The second row is superfluous as it is the first row negated. It exist just to be aligned with multi-class SupervisedClassifiers. Each column in input and output corresponds to a sample to predict. Each row in input corresponds to a training sample, and more exactly row i in input should correspond to row i in KernelLookup that was used for training.
| void theplu::yat::classifier::SVM::reset | ( | void | ) |
make SVM untrained
Setting variable trained to false; other variables are undefined.
- Since:
- New in yat 0.6
| void theplu::yat::classifier::SVM::train | ( | const KernelLookup & | kernel, |
| const Target & | target | ||
| ) |
Training the SVM following Platt's SMO, with Keerti's modifacation. Minimizing 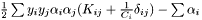 , which corresponds to minimizing
, which corresponds to minimizing 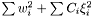 .
.
- Note:
- If the training problem is not linearly separable and C is set to infinity, the minima will be located in the infinity, and thus the minimum will not be reached within the maximal number of epochs. More exactly, when the problem is not linearly separable, there exists an eigenvector to
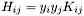 within the space defined by the conditions:
within the space defined by the conditions: 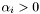 and
and 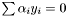 . As the eigenvalue is zero in this direction the quadratic term does not contribute to the objective, but the objective only consists of the linear term and hence there is no minumum. This problem only occurs when
. As the eigenvalue is zero in this direction the quadratic term does not contribute to the objective, but the objective only consists of the linear term and hence there is no minumum. This problem only occurs when 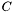 is set to infinity because for a finite all eigenvalues are finite. However, for a large (and training problem is non-linearly separable) there exists an eigenvector corresponding to a small eigenvalue, which means the minima has moved from infinity to "very far away". In practice this will also result in that the minima is not reached withing the maximal number of epochs and the of should be decreased.
is set to infinity because for a finite all eigenvalues are finite. However, for a large (and training problem is non-linearly separable) there exists an eigenvector corresponding to a small eigenvalue, which means the minima has moved from infinity to "very far away". In practice this will also result in that the minima is not reached withing the maximal number of epochs and the of should be decreased.
Class for SVM using Keerthi's second modification of Platt's Sequential Minimal Optimization. The SVM uses all data given for training.
- Exceptions:
-
utility::runtime_error if maximal number of epoch is reach.
| bool theplu::yat::classifier::SVM::trained | ( | void | ) | const |
- Returns:
- true if SVM is trained
- Since:
- New in yat 0.6
The documentation for this class was generated from the following file:
- yat/classifier/SVM.h
