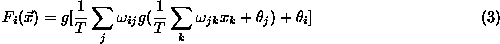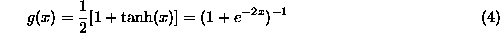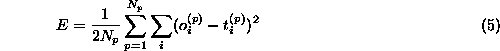When analyzing experimental data the standard procedure is to make various cuts
in observed kinematical variables 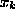 in order to single out desired
features. A specific selection of cuts corresponds to a particular set of feature
functions
in order to single out desired
features. A specific selection of cuts corresponds to a particular set of feature
functions 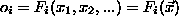 in terms of the
kinematical variables
in terms of the
kinematical variables 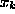 . This procedure is often not very systematic and
quite tedious. Ideally one would like to have an automated optimal choice of the
functions
. This procedure is often not very systematic and
quite tedious. Ideally one would like to have an automated optimal choice of the
functions 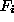 , which is exactly what feature recognition ANN aim at. For
a feed-forward ANN the following form of
, which is exactly what feature recognition ANN aim at. For
a feed-forward ANN the following form of 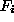 is often chosen
is often chosen
which corresponds to the architecture of fig. ![]() . Here the ``weights''
. Here the ``weights''
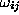 and
and 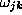 are the parameters to
be fitted to the data distributions and
are the parameters to
be fitted to the data distributions and 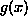 is the non-linear neuron
activation function, typically of the form
is the non-linear neuron
activation function, typically of the form
The bottom layer (input) in fig. ![]() corresponds to sensor
variables
corresponds to sensor
variables 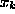 and the
top layer to the (output) features
and the
top layer to the (output) features 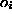 (the feature functions
(the feature functions 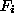 ).
The hidden layer enables non-linear modeling of the sensor data.
Eq. (
).
The hidden layer enables non-linear modeling of the sensor data.
Eq. (![]() ) and fig.
) and fig. ![]() are easily generalized to more than
one hidden layer.
are easily generalized to more than
one hidden layer.
Using eq. (![]() ) for the output assumes that the output variables
represent classes and are of binary nature. The same architecture can
be used for real function mapping if
) for the output assumes that the output variables
represent classes and are of binary nature. The same architecture can
be used for real function mapping if 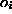 are chosen linear, in which
case the outermost g is removed from the left hand side of (
are chosen linear, in which
case the outermost g is removed from the left hand side of (![]() ).
).
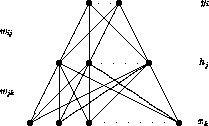
Figure: A one hidden layer feed-forward neural network architecture.
The weights 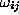 and
and 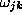 are determined by minimizing
an error measure of the fit, e.g. a mean square error
are determined by minimizing
an error measure of the fit, e.g. a mean square error
between 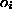 and the desired feature values
and the desired feature values 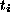 (targets) with respect
to the weights. In eq. (
(targets) with respect
to the weights. In eq. (![]() )
) 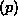 denotes patterns. For architectures
with non-linear hidden nodes no exact procedure exists for minimizing the
error and one has to rely on iterative methods, some of which are described
below.
denotes patterns. For architectures
with non-linear hidden nodes no exact procedure exists for minimizing the
error and one has to rely on iterative methods, some of which are described
below.
Once the weights have been fitted to the data in this way, using labeled data, the network should be able to model data it has never seen before. The ability of the network to correctly model such unlabeled data is called generalization performance.
When modeling data it is always crucial for the generalization performance
that the number of data points well exceeds the number of parameters (in our
case the number of weights 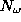 ). For a given set of sensor variables
this can be accomplished by
). For a given set of sensor variables
this can be accomplished by